
Google Summer of Code
The FrameNet Brasil Computational Linguistics Lab at the Federal University of Juiz de Fora, Brazil, has applied as a mentor organization for Google Summer of Code 2022. This page is the main reference point for students submitting their projects to address the ideas listed below.
1. FrameNet 101
A framenet is a semantically oriented computational resource in which language material (words, multi-word expressions and grammatical constructions) are linked to a network of frames that help define their meaning. In the context of Frame Semantics, a frame is a scene, a system of interrelated concepts in which participants on the scene, the props they use, and the way they interact are defined. The key notion in framenet is that the meaning of words – as well as the meaning of other levels of linguistic structure – depends on the frames associated with the words, that is, words may evoke frames. Take a word such as the verb tour, for example. In order to understand this word, a speaker of English recruits the Touring frame, in which there are three core participants: the Tourist, an Attraction and a Place. These three elements must be cognitively present, so that the idea of touring can be interpreted. There’s no tourism without one of those elements. Additionally, frames are interconnected to each other via a series of relations, providing a cognitive semantics structure against which meaning is defined.
In FrameNet Brasil we extend this notion to other communication modes, namely image and video, and apply this kind of semantically oriented structure to tackle important issues in Natural Language Understanding. In the ideas list below, we explain those issues further.
To learn more about FrameNet Brasil, consider the following papers:
TORRENT, T. T.; MATOS, E.; LAGE, L.; LAVIOLA, A.; TAVARES, T.; ALMEIDA, V. G.; SIGILIANO, N. (2018). Towards continuity between the lexicon and the constructicon in FrameNet Brasil. In: LYNGFELT, B.; BORIN, L.; OHARA, K. H.; TORRENT, T. T. (Orgs.). Constructional Approaches to Language. Amsterdam: John Benjamins Publishing Company.
BELCAVELLO, F.; VIRIDIANO, M.; DINIZ DA COSTA, A.; MATOS, E. E.; TORRENT, T. T. (2020). Frame-Based Annotation of Multimodal Corpora: Tracking (A)Synchronies in Meaning Construction. In: Proceedings of the LREC International FrameNet Workshop 2020: Towards a Global, Multilingual FrameNet. Marseille, France: ELRA, p. 23-30.
There are framenets under development for several languages (English, Japanese, German, Swedish, Brazilian Portuguese, Chinese, among others) and also a global initiative to connect them all and develop shared tasks based on framenet data. To learn more about this initiative, visit the Global FrameNet website.
2. How to Apply
Successful applicants will turn in projects to address the issues listed in the ideas list, bringing together the kind of structured data FN-Br has been developing through the past decade with the computational techniques they find more suited for achieving the proposed goals. Please note that FN-Br is not only about big data, machine learning and whichever purely statistical approach to language is out there. The work in FN-Br is model-based, besides being also data-driven. The kinds of issues prompting the mentoring process that will take place if FN-Br is accepted for GSoC 2022 are not to be solved by solely training some algorithm from a ton of raw data. With that in mind, applicants should follow the steps below to submit their applications:
Read all the links, papers and instructions given on this document
We’ve tried to give you all the information you need to be an awesome GSoC contributor.
- Look at the data reports and familiarize yourself with the kind of structure FN-Br builds;
- Read the GSoC Student Guide;
- Read the FrameNet Contributors Covenant Code;
- Read the following papers:
- Towards continuity between the lexicon and the constructicon in FrameNet Brasil. TORRENT, T. T.; MATOS, E.; LAGE, L.; LAVIOLA, A.; TAVARES, T.; ALMEIDA, V. G.; SIGILIANO, N. (2018). In: LYNGFELT, B.; BORIN, L.; OHARA, K. H.; TORRENT, T. T. (Orgs.). Constructional Approaches to Language. Amsterdam: John Benjamins Publishing Company.
- Frame-Based Annotation of Multimodal Corpora: Tracking (A)Synchronies in Meaning Construction. BELCAVELLO, F.; VIRIDIANO, M.; DINIZ DA COSTA, A.; MATOS, E. E.; TORRENT, T. T. (2020). In: Proceedings of the LREC International FrameNet Workshop 2020: Towards a Global, Multilingual FrameNet. Marseille, France: ELRA, p. 23-30.
Choose an Idea (see section 3 below)
Constributions not associated with any of the FrameNet Brasil proposed ideas typically get rejected.
Talk with your prospective mentors
Join the FrameNet GSoC Slack community and ask the mentors about what they expect of GSoC contributors. Get help from them to refine your project ideas. It is a good idea to start on your proposal early, post a draft to the FrameNet Slack community and tag one of the mentors, so they can review it and iterate based on the feedback you receive. This will only improve the quality of your proposal. Listening to your mentors’ recommendations is very important at this stage!
📍Communication is probably the most important part of the application process and the mentor is one of the most valuable resources for GSoC projects. Talk to the mentors and other developers, listen when they give you advice, and demonstrate that you’ve understood by incorporating their feedback into what you’re proposing. The mentor likely has worked on the project for long enough to know the history of decisions, how things are architected, the other people involved, the process for doing things, and all other cultural lore that will help constributors be most successful.
Also, make it easy for your mentors to give you feedback. If you’re using Google docs, enable comments and submit a “draft” (we can’t see the “final” versions until applications close). If you’re using a format that doesn’t accept comments, make sure your email is on the document and don’t forget to check for feedback!
We usually reject applicants who haven’t listened to mentor feedback. If your mentors tell you that a project idea won’t work for them, you’re probably not going to get accepted unless you change it.
Write your application
Write a 1-3 pages pre-project (take a look at the GSoC Sample Application Template) and submit it to projeto.framenetbr@ufjf.br, one week before the official submission deadline to get feedback from FN-Br before the official submission.
Submit your application to Google before the deadline (April 19 – 18:00 UTC)
We actually recommend you submit a few days early in case you have internet problems or the system is down. Google does not extend this deadline, so it’s best to be prepared early! You can edit your application up until the system closes.
Note: All applications must go through Google’s application system; we can’t accept any application unless it is submitted there.
3. Ideas List
There are important aspects to keep in mind while reading the ideas described below.
The core of the FN-Br data model includes four entities: Frames, Frame Elements, Lexical Units (LU) and images (either pictures or videos). Frames (representing the meaning of a scene or event) are composed of Frame Elements (participants in the scene or event). Lexical Units represent the association – or pairing – of a word or multiword expression with a Frame. Sentences in a given language containing any LU can be annotated for their frames and frame elements. The basic annotation process of a sentence consists of choosing a specific word in the sentence (the target Lexical Unit) and associating semantic labels (Frame Elements) to the other words/expressions in the sentence that are somehow dependent on the target.
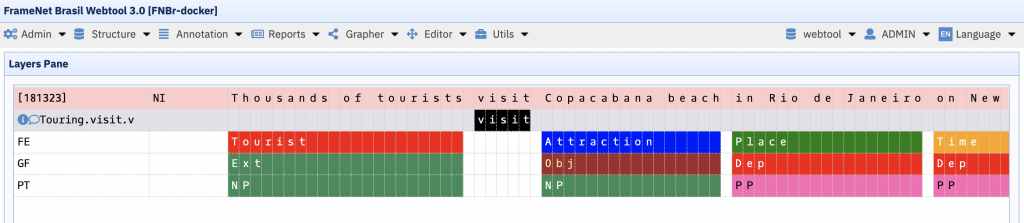
Originally, only sentences (i.e. texts) were annotated in FN-Br. Nonetheless, since GSoC 2019, the FN-Br Web Annotation Tool also features a module for annotating multimodal corpora, that is, a video plus the transcripts of the audio or the subtitles superimposed on it, that is, picture-caption pairings. The set of annotated target LU/image element plus Frame Elements is called an AnnotationSet. As many words and/or image fragments in the sentence can be chosen as targets, it is possible that many AnnotationSets are associated with one sentence or video fragment.
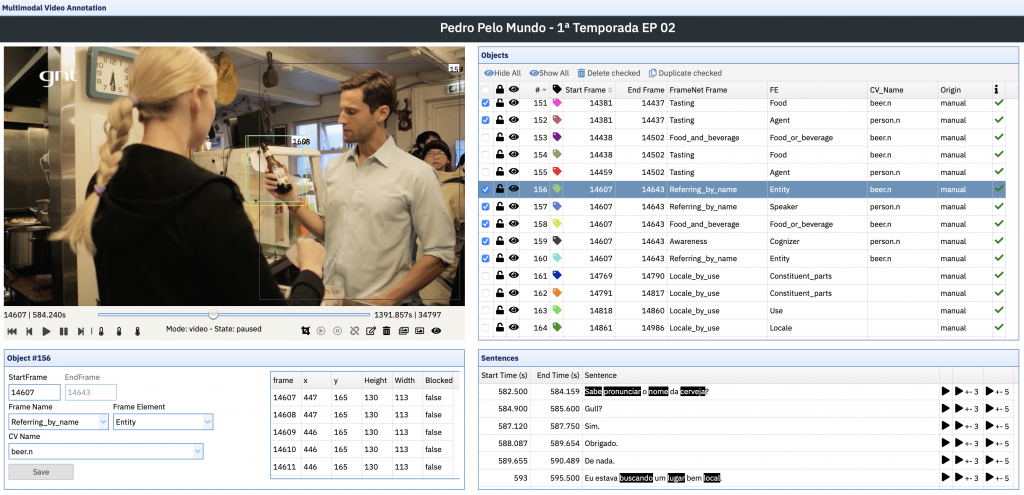
Once you are familiar with the kinds of (meta)data you’ll be working with, you should explore the ideas presented below.
3.1. Anomaly and Redundancy Estimation for Newly Created Frames using AI
Mentors: Arthur Lorenzi (FN-Br | UFJF) | Ely Matos (FN-Br | UFJF) | Tiago Torrent (FN-Br | UFJF) | Mark Turner (Red Hen | CWRU)
Expected proposal type: 350 hours project
Difficulty rating: Hard
Skillset: Python, JavaScript, SQL, and version control system (Git).
General Context:
FN-Br has developed Lutma, a frame maker tool that allows people to contribute frames and lexical units to a multilingual data release, to be made available soon as part of Global FrameNet. In the future, when a new frame is created, people in the framenet community will be able to suggest edits and revise the new frames. However, if the volume of newly created frames is too big, some sort of automatic identification of potentially anomalous or redundant frames will be needed.
The Idea:
This idea proposes the development of an AI model trained on framenet structure data (frame names and definitions, frame element names and definitions, frame-to-frame relations, and lexical units) to detect anomalous and redundant frames in Lutma, flag them, and provide contributors with a report of why the newly created frame has been flagged.
Why this Idea is Innovative:
The innovation presented by this idea relies on the fact that instead of using annotated data for training an AI model based on framenet, it proposes exploiting the richness of the semantic representation provided by FrameNet itself to improve the quality of human-made frames. It also has a training impact on the community of contributors, since the report generated by the system can help identify and correct potential errors in the frame creation process.
3.2. Enhancing FrameNet Data Visualization
Mentors: Ely Matos (FN-Br | UFJF) | Collin Baker (FrameNet | ICSI) | Marcelo Viridiano (FN-Br | UFJF)
Expected proposal type: 350 hours project
Difficulty rating: Hard
Skillset: Python, JavaScript, SQL, and version control system (Git).
General Context:
FrameNet data is rich and dense. All this richness, plus the network structure of FrameNet, makes traditional list- and table- based data visualization inadequate. The underlying relational database also makes certain types of queries difficult to code. Also, as the FrameNet Brasil Web Annotation Tool has been used for other projects, including the Global FrameNet Shared Annotation Task, new data compatibility features have been demanded by the community.
The Idea:
This idea involves a partial migration from the current FN database to a graph database. This would simplify some common graph traversals like testing reachability, finding shortest paths between frames or frame elements, and recognizing patterns of polysemy of lexical units. Having both a graph database and graphical visualizations of it will make it easy to move back and forth between them, in much the same way that analytic geometry makes it easy to move between the equation of a function and its graph. The visualization tool can be built outside the FrameNet Brasil WebTool, and will ideally have applications to other complex lexical databases besides FrameNet.
Why this Idea is Innovative:
Two partial visualizations are available on the ICSI FrameNet website, the FrameGrapher and the Frame Lattice list. However, no suitable data visualization tool has been built which will illuminate the whole complex structure of Frame Semantic data, including annotation sets. These tools would help to clearly display that structure and meet the urgent need to link the fine-grained semantic representations of FrameNet with other semantic resources and computational tools.
3.3. Measuring Frame Semantic Similarity in Multimodal, Multilingual Corpora
Mentors: Marcelo Viridiano (FN-Br | UFJF) | Fred Belcavello (FN-Br | UFJF) | Oliver Czulo (Uni-Leipzig) | Zheng-Xin Yong (Brown University) | Debanjana Kar (IBM Research) | Tiago Torrent (FN-Br | UFJF)
Expected proposal type: 350 hours project
Difficulty rating: Hard
Skillset: Python, JavaScript, SQL, and version control system (Git).
General Context:
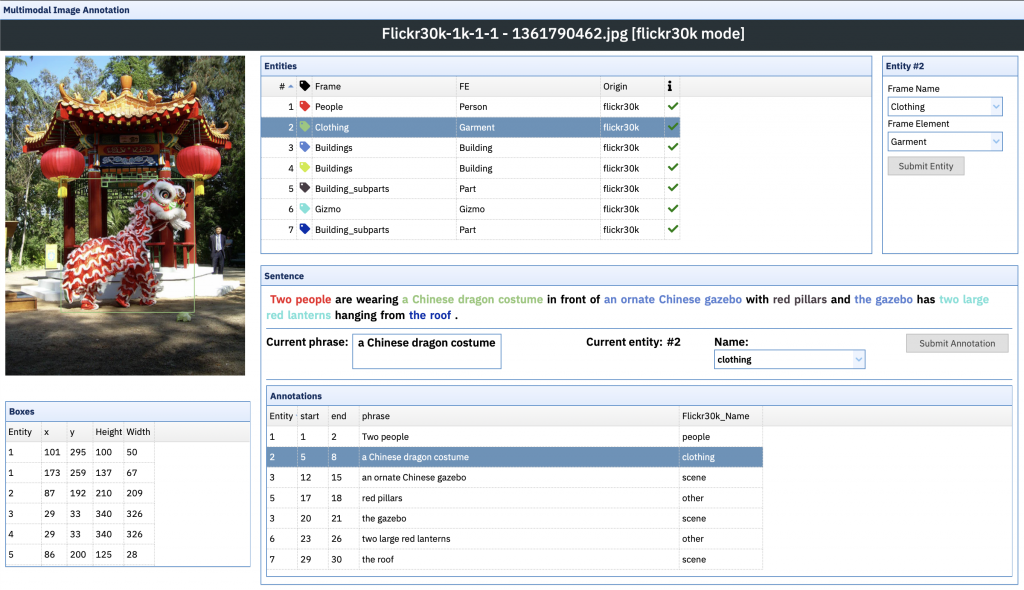
FN-Br has been annotating the Fickr 30k Entities corpus for frames and frame elements. In collaboration with the University of Leipzig, we’ve been also extending such annotation to the Multi30k corpus, where captions originally produced in English for the Flickr30k images are translated into other languages, including German and Brazilian Portuguese.
The resulting data set will be composed of: (a) 1,000 pictures with bounding boxes identifying elements in them; (b) annotations of each bounding box for frames and frame elements; (c) 2,000 captions in English, two per image, annotated for frames; (d) 2,000 captions for Brazilian Portuguese and 2,000 for German, two per image, currently under annotation for frames.
The Idea:
For this idea, we expect projects focused on extracting semantic similarity (and variation) across (a) communicative modes – image and verbal language – and (b) languages. The task is to implement algorithms for the assessment of semantic similarity between and variation within image descriptions for (1) descriptions in one language, (2) descriptions in one or another language in reference to a gold-standard description and (3) descriptions in different languages. (3) is a stretch goal.
Why this Idea is Innovative:
The assessment of semantic similarity in the FrameNet context is not addressed by means of (solely) word embedding models, but by rich, often culturally loaded categories called frames. These categories allow for certain, though abstract and probabilistic predictions of the behavior and the interpretation of the semantics of a linguistic stimulus. On top of this, the network structure of frames models semantic connections between these rich categories. With this project, we want to leverage this information for research into a type of task which can be applied to various scenarios beyond the assessment of image descriptions.